
We Chose Kubernetes Because It Was the Right Technology. And that Was the Wrong Reason.
We chose Kubernetes because it was the right technology. We were asking the wrong question. Eight engineers, one internal system, and months of hidden costs that never appeared on any invoice. Here is what that taught us about technology decisions.

This is part of The True Code of a Complete Engineer. The series is about the things I wish someone had told me earlier.
We were asking the right question incorrectly.
The question we asked was: is Kubernetes the right technology for this system?
The answer was yes. Kubernetes is genuinely good at what it does. Scalable. Flexible. The kind of infrastructure that serious engineering teams build on. We had done our research. We had read the documentation. We understood what it offered.
But that was not the question we needed to ask. And by the time we understood what the right question was, we had spent months finding out the expensive way.
This is not a post about Kubernetes being wrong. It is a post about how technology decisions get made, and why the way most teams make them is quietly broken in a way that does not show up until it is already costing them.
The Decision
We were building an internal system from scratch. Eight engineers. A greenfield project, which meant we got to choose everything. The stack, the architecture, the deployment strategy. That kind of freedom feels like a gift. Looking back, it is also where the expensive mistakes tend to live.
When the conversation came to infrastructure, the answer felt straightforward. Docker and Kubernetes. Azure Kubernetes Service specifically, since we were already on Azure. This was the modern approach. Containerisation gave us consistency across environments. Kubernetes gave us orchestration, scaling, clean service management. The ecosystem was mature. The community was large. The documentation was comprehensive.
The architecture diagram looked exactly like it was supposed to look.
Nobody pushed back. Because on paper, the reasoning was sound. The technology was good. The team was capable. The decision felt right in the way that decisions feel right when you have evaluated the technology carefully and found nothing wrong with it.
And that is exactly where we went wrong. We evaluated the technology. We did not evaluate the fit.
What We Did Not Ask
There are questions that should happen before any technology decision. They are not complicated questions. They are not hidden anywhere. But they are almost never the questions being asked when the architecture diagram goes up on the screen and the conversation starts.
We did not ask what this system actually needed.
It was an internal system. Eight engineers. Real workload, real users, real business value. But not the kind of scale that demands what Kubernetes offers. We were not running a hundred microservices. We were not managing traffic spikes that required dynamic pod scaling at three in the morning. We were building something that needed to work reliably and be maintainable by the people in the room, for years, without heroics.
The system did not need what we were about to build it on.
We did not ask what the team could actually own.
Kubernetes is genuinely complex. Not complicated in the way that anything new feels complicated for the first week and then becomes familiar. Complex in the way that takes sustained, deliberate investment to understand deeply. Two engineers on the team went furthest into it. The rest had enough knowledge to follow a runbook in a known situation. Not enough to diagnose something unexpected without going back to those two people.
That asymmetry felt manageable in the beginning. It stopped feeling manageable around month three.
We did not ask what it would cost. Not just the Azure bill.
The Real Cost of a Technology Choice
This is the part that never makes it into the architecture discussion. And it should, every time, before anyone draws the first box on the whiteboard.
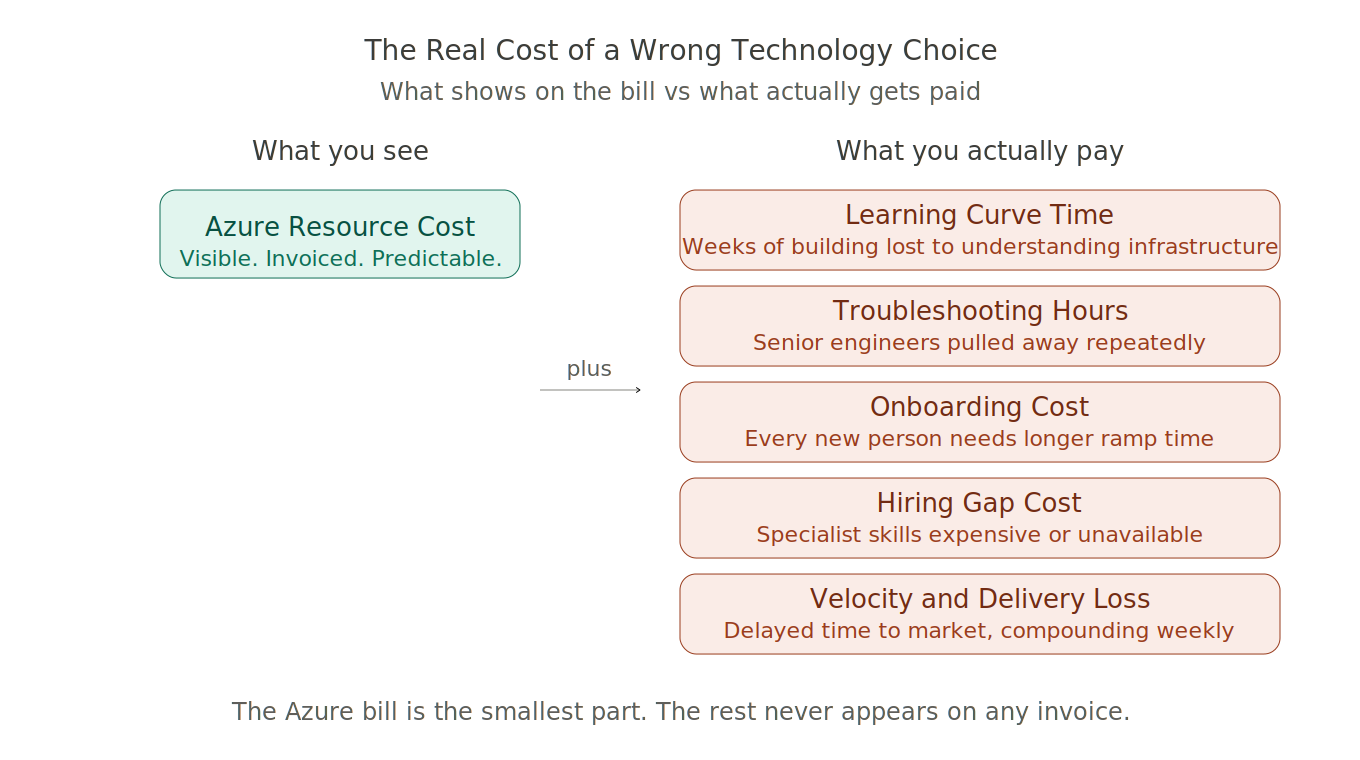
The Azure bill was real. AKS clusters carry overhead that simpler deployment options do not. Node pools, the control plane, the networking configuration. For an internal system at our scale, that overhead was pure cost with no corresponding benefit we were actually using. It showed up every month, predictably, on a line item that everyone could see.
But the Azure bill was the smallest part of it.
The learning curve cost came first. Kubernetes is not something you pick up alongside delivering a project on a fixed timeline. Learning it properly takes sustained time and attention. The hours the team spent reading documentation, watching tutorials, working through configuration problems, trying to understand why something was behaving unexpectedly in the development environment, those were hours not spent building the system we were hired to build. That cost does not appear on any invoice. It shows up in velocity. In standups where progress is slower than it should be and nobody can quite articulate why. In the gap between what the timeline said and what actually shipped.
The troubleshooting cost compounded it. Every developer who hit an infrastructure issue and could not resolve it independently needed to pull in one of the two people who knew Kubernetes deeply. That is a hidden tax on your most knowledgeable engineers, paid continuously, invisibly, every single week. The people most capable of building the hard parts of the system were also the people most frequently pulled away from building anything.
The onboarding cost multiplied it. Every new person who came into the system needed time to understand the infrastructure layer before they could contribute meaningfully. That ramp was longer than it needed to be. It had a cost. When you multiply it across everyone who touched the project, it becomes significant in a way that is easy to miss when you are only counting it one person at a time.
Then there was the hiring question. If we were going to run this properly over the long term, we needed engineers who knew AKS deeply. Not one or two people who had gone furthest into it. Multiple people who could own it with genuine confidence. We looked at what that would take. The engineers with real production AKS experience were expensive, and justifiably so. The skill is real and the market reflects that. But expensive relative to what an internal system at our scale could justify. The hire we needed would cost more than the problem it would solve was worth.
And underneath all of it was the velocity cost. Every week that the team was moving slower than it should, every feature that took longer than planned, every delivery that slipped because the infrastructure was consuming time that should have gone into the product. That has a cost too. In delayed delivery, in compounding schedule pressure, in the quiet erosion of confidence that happens when a capable team is consistently moving more slowly than everyone expected.
Add it together. Resource costs. Learning curve. Troubleshooting hours. Onboarding ramp. Hiring gap. Velocity loss. Delayed time to market.
That is what a technology choice that does not fit the context actually costs. It does not arrive as a single line item. It distributes itself across everything, quietly, until someone finally sits down and adds it up.
There is a useful parallel here with 5 Critical Things to Check if You Want to Optimize the Performance of an Existing System, the bottlenecks that hurt you most are rarely the obvious ones. They are the ones quietly accumulating in the background while you are looking somewhere else.
The Slow Realization
There was no single moment. That is the honest answer, and I think it is important to say it clearly because most stories about decisions like this have a dramatic turning point. Ours did not.
It was the fourth time in two months that a development environment issue had consumed most of a day. It was the conversation where someone asked a straightforward question about a deployment configuration and the answer required getting three people on a call. It was the sprint retrospective where the team kept circling back to the same friction without being able to name it precisely. It was the growing sense, which nobody said out loud for a long time, that the infrastructure had become the project, without anyone deciding that was what we wanted.
Somewhere in that accumulation, the question shifted.
We stopped asking how to make Kubernetes work for us. We started asking whether it was the right choice for where we actually were. Eight engineers. An internal system. A team with deep domain knowledge and real capability, but without the Kubernetes expertise to operate it without ongoing cost that the system could not justify.
When we put it that way, the answer was uncomfortable but clear.
The slow accumulation of small friction before a decision becomes unavoidable is something I wrote about in the context of production incidents too. In The First Thing You Should Do in a Production Incident Is Not What You Think, the same pattern shows up, the instinct to act immediately before you have understood the full picture is exactly what makes situations worse. The slower, more deliberate approach to understanding what is actually happening is almost always the right one.
The Decision to Move
Azure App Service did not carry the same learning curve. The infrastructure concepts were simpler to reason about. The deployment pipeline was something the whole team could understand and maintain without specialist knowledge. When something went wrong, more people could diagnose it. The problem surface was smaller and the path to a fix was accessible to more than two people.
It was not the exciting choice. Nobody writes conference talks about choosing App Service. There is no architecture diagram that makes it look as impressive as a Kubernetes cluster. And there is a version of engineering culture where that matters, where the impressiveness of the infrastructure choice is part of how a team thinks about itself.
We chose to care about something else. We chose to care about whether eight engineers could build and ship and operate a system without the infrastructure sitting between them and the work. And for this system, with this team, at this moment, that was the thing that actually mattered.
The decision to move was uncomfortable in the way reversals always are. There is a version of engineering culture where changing your mind is treated as failure. Where the original decision becomes something to defend rather than examine honestly. Where admitting that a choice did not fit feels like admitting something worse than a simple mistake.
We chose not to do that. We moved. The team already knew how. That, in itself, told us something.
What Changed
Development velocity improved. Not because App Service is inherently faster to build on, but because the team could move without the infrastructure layer sitting between them and the work.
Onboarding became simpler. Anyone on the team could look at the deployment setup and understand it fully. There was no longer a subset of knowledge that lived with a subset of people and had to be transferred carefully every time someone new arrived.
The cost picture changed across every dimension. Lower resource costs. Developer hours returning to the actual work. Learning curve gone. Velocity back to where it should have been from the start. The compounding weight of all those hidden costs, which had been accumulating quietly for months, stopped accumulating.
The background friction went away. That is harder to measure than anything else, but it was the most noticeable change. The low-level awareness that the infrastructure required specialist attention, that certain things needed to go through certain people, that an unexpected issue might consume a day nobody had budgeted for. When it left, the whole team felt it.
The Questions That Should Have Been Asked First
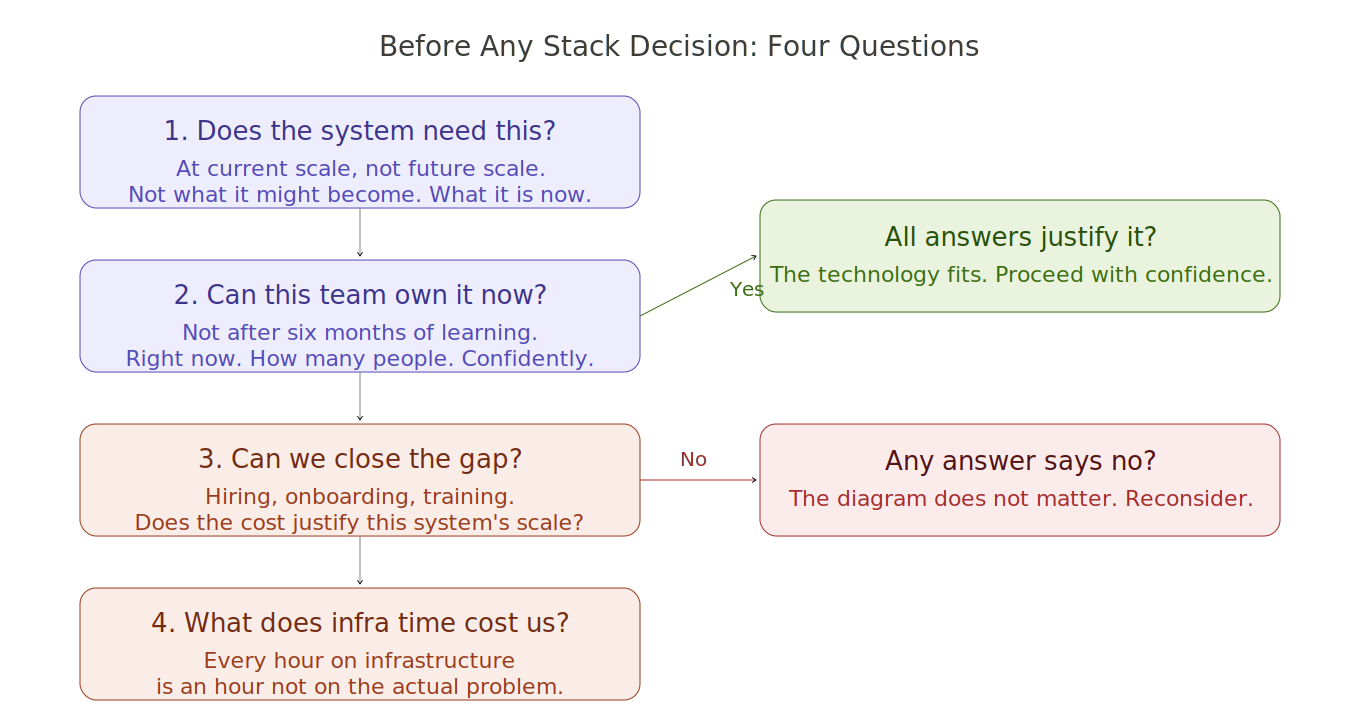
Before any stack decision, there are four questions worth asking honestly. Not after the architecture diagram is drawn. Before it.
What does this system actually need at its current scale, not its projected future scale? A system that might grow is not the same as a system that has grown. Building for what might happen in three years costs you in the present. Get the present right first.
What can this team confidently own right now, not after six months of learning? The team you have is the team that will run this. If the technology requires expertise the team does not have, that gap will cost you. The question is whether that cost is justified by what the technology gives you back.
What will closing the expertise gap actually cost, across hiring, onboarding, and the time of the people already there? This is the question that reveals whether the choice makes sense at the scale you are building at. If the answer is that closing the gap costs more than the gap is worth, that is important information.
How much of the team's time will go into the infrastructure instead of the problem they were hired to solve? This is the question nobody asks. Every hour on infrastructure is an hour not on the actual system. That trade needs to be explicit and justified, not accidental.
These questions apply beyond infrastructure too. The same thinking applies when deciding whether to migrate a monolith to microservices, whether to adopt a new cloud service, or whether to introduce a new architectural pattern. Should I Migrate My Monolithic Application to Microservices? explores exactly this kind of decision from the same angle.
The Real Lesson
Technology stack selection is not a technology decision. It is a total cost decision.
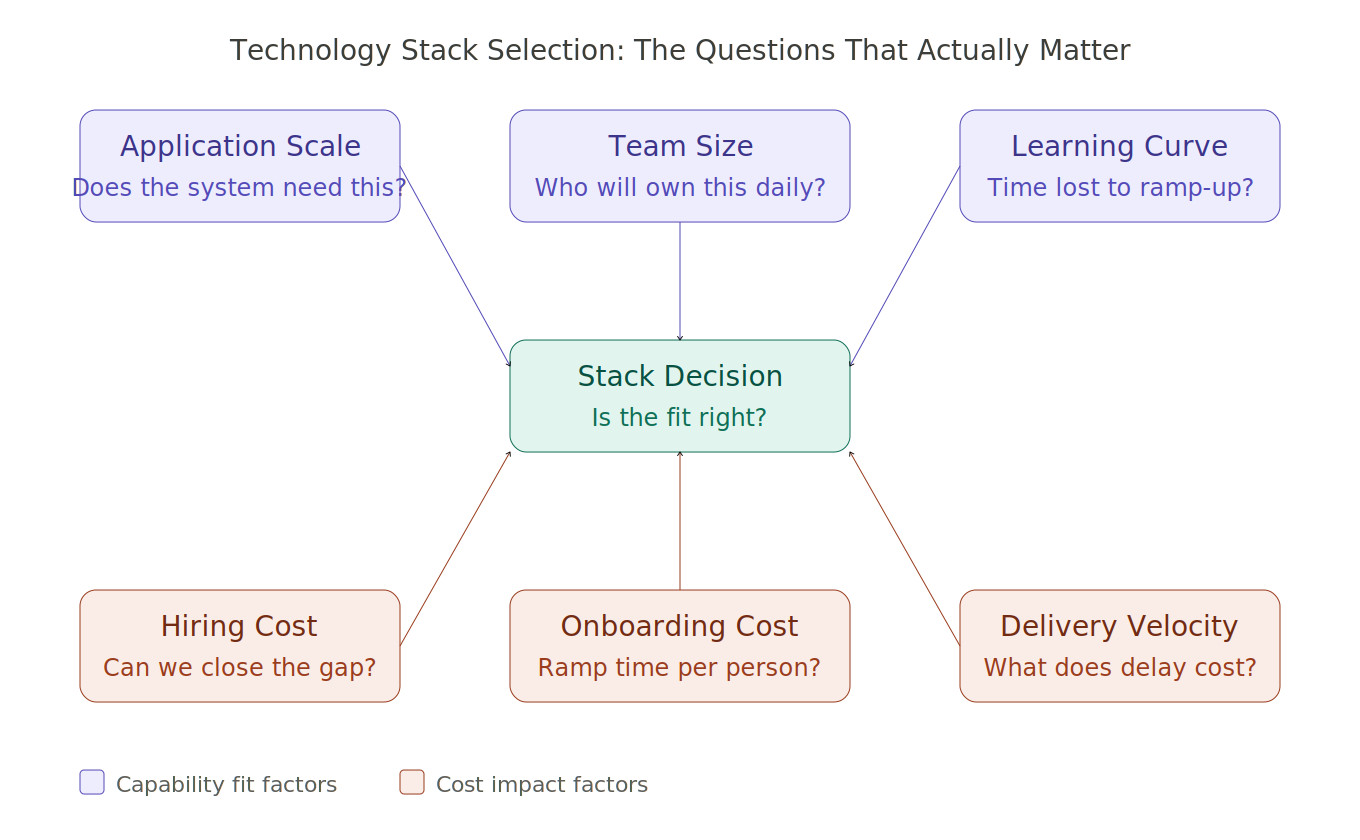
Total cost is not what appears on the cloud bill at the end of the month. It is everything the choice asks of the team. The learning curve. The hiring gap. The onboarding time. The developer hours diverted from building to understanding infrastructure. The velocity lost to a complexity the system did not need. The delayed delivery that follows all of it, week after week, compounding quietly.
When we chose Kubernetes, we evaluated the technology correctly. We did not evaluate the fit. We did not ask whether this system, at this scale, with this team, actually needed what Kubernetes offers. We did not ask what it would cost us in all the ways that do not show up on any invoice.
The technology was right. The fit was wrong. And a technology that is right for the wrong context is still the wrong choice.
We found that out during development, before it became a production problem. That, at least, was the right time to find it.
The diagram on the whiteboard will always look better than the reality of eight engineers trying to operate infrastructure that two of them understand deeply. Make sure the choice reflects the reality, not the diagram.
You May Also Find These Useful
From The True Code of a Complete Engineer series:
The Blind Spot That Slowed Me Down for Years — On the vocabulary and navigation gaps that quietly cost engineers more time than any technical problem.
The First Thing You Should Do in a Production Incident Is Not What You Think — On why acting fast before understanding the full picture is how good engineers make situations worse.
You're Not Junior. You Just Don't Have the Words. — On why technical vocabulary is a career skill, not just a learning detail.
From The True Code of Production Systems series:
CQRS Simplified the Design. It Complicated Production. — The same pattern of a decision that looks right on the whiteboard meeting the reality of running it every day.
Caching Is Easy. Production Caching Is Not. — On how every production decision has more dimensions than the one you consciously made.
From the blog:
Why On-Call-Friendly Systems Are the Real Measure of Good Architecture — Architecture is not just what you build. It is what the team can operate at two in the morning.
Should I Migrate My Monolithic Application to Microservices? — The same four questions applied to one of the most common architecture decisions in engineering teams.
System Thinking Is Not Architecture — And That's Why Most Architects Get It Wrong — On why the ability to think about systems as a whole is different from the ability to draw them.
The True Code of a Complete Engineer is a series about the things I wish someone had told me earlier. Not theory. The real lessons that shaped how I grew, earned trust, and learned to lead.
Read the full series at The True Code of a Complete Engineer.